CodeXamarin – Master Xamarin & .NET MAUI with free tutorials, code examples, and step-by-step guides for Android, iOS, and cross-platform mobile development. Start building apps today!
Pixels — (Google Definition)a minute area of illumination on a display screen, one of many from which an image is composed.
Screen Resolution — Resolution is always referred in x*y form, which means x is the number of pixels in horizontal direction and y is the number of pixels in a vertical direction. Example — HD display 1920*1080 = 2,083,600 is the total pixels on screen
Pixels per inch — This is the measurement of the pixel density(resolution). Example — I have an image of 100*100 pixel which I need to print on a 1-inch square. Now, it will have a resolution of 100 pixels per inch.
You can set the child size by using specific units when you need the child to manage its own size. Android lets you specify sizes in pixels (px).
<Buttonandroid:layout_width="100px"... />
However, Android's best-practice guidelines recommend that you avoid using px.
Through this terminologies, we can say that now we can design the UI for Android based on the pixels of the displaying screen. But, this world consists of a variety of display screen sizes which is not possible for us to design with.
In Android Development, we have seen many developers using dp as a measurement unit for all the views. But, what’s dp? what's sp? And how this dp/sp helps us to achieve the same size in different screen sizes?
A density-independent pixel (dp) is a unit of measure. When rendered to the screen, objects that are measured in density-independent pixels use the number of physical pixels calculated from the screen's pixel density.
Suppose you defined the following button in your UI:
<Buttonandroid:layout_width="100dp"... />
The goal for the button is to occupy about the same area on the screen regardless of the device's screen density. On a high-resolution screen, this button would occupy more than 100 physical pixels.
A button with a width of 100 dp will appear about the same size on a 500-dpi screen and a 250-dpi screen. It will occupy a different number of physical pixels in the two cases to achieve the required size.
Android best-practice guidelines recommend that you use density-independent pixels to specify sizes.
Let’s see the relation between pixels and density-independent pixels
Taking an example of three devices of the same physical size but different resolution.
If I define my Button’s height and width in pixel, this is going to happen in different device resolution. Button covers 2 pixels horizontally and 2 pixels vertically but the pixel density(resolution) is different which makes our button size small.
So, what’s the solution here? Now, I will use dp as a measurement unit.
Here, we can see the size of the button is the same in all the devices. What Android has done here is, map the number of pixels.
There is one more unit called SP. What is sp? And when should we use sp? And when should we use dp?
Scale Independent Pixels —This is same as dp, but by default, android resizes it based on the font size of the user’s phone.
sp is only used for the text, never use it for the layout sizes.
In Android, we have a baseline density of 160 dots-per-inch(dpi). So, for a 160 dpi screen, we have 1 pixel = 1 dp and 320 dpi screen, we have 2 pixels = 1 dp which is 2x.
px = dp * (dpi / 160)
Let’s say we have a tablet of 1280*800 pixels, 160 dpi and phone of 800*1280 pixels, 320 dpi. Their pixel resolution is the same. But, what will be in the dp?
Tablet is of 160 dpi which is baseline so, 1280*800 dp but the phone is of 320 dpi which is half, 400*640dp. This helps us to design the layout for a tablet and phone very quickly. We can also think of a screen of 1280 dp versus 400 dp.
Let’s say we have two devices of the same size but different resolution. One is 400*640 pixels, 160 dpi and another is 800*1280 pixels, 320 dpi.
Now, if we convert this in density-independent pixels, we have the same size of 400*640 dp. This makes us design a single layout for both the screens.
Now, we can understand the meaning of Density Independent Pixels, (Pixels not depending on the density)
Sometimes, there are more than one way to solve a problem. We need to learn how to compare the performance different algorithms and choose the best one to solve a particular problem. While analyzing an algorithm, we mostly consider time complexity and space complexity. Time complexity of an algorithm quantifies the amount of time taken by an algorithm to run as a function of the length of the input. Similarly, Space complexity of an algorithm quantifies the amount of space or memory taken by an algorithm to run as a function of the length of the input.
Time and space complexity depends on lots of things like hardware, operating system, processors, etc. However, we don't consider any of these factors while analyzing the algorithm. We will only consider the execution time of an algorithm.
Lets start with a simple example. Suppose you are given an array and an integer and you have to find if exists in array .
Simple solution to this problem is traverse the whole array and check if the any element is equal to .
for i :1 to length of A
if A[i]is equal to x
return TRUE
return FALSE
Each of the operation in computer take approximately constant time. Let each operation takes time. The number of lines of code executed is actually depends on the value of . During analyses of algorithm, mostly we will consider worst case scenario, i.e., when is not present in the array . In the worst case, the if condition will run times where is the length of the array . So in the worst case, total execution time will be . for the if condition and for the return statement ( ignoring some operations like assignment of ).
As we can see that the total time depends on the length of the array . If the length of the array will increase the time of execution will also increase.
Order of growth is how the time of execution depends on the length of the input. In the above example, we can clearly see that the time of execution is linearly depends on the length of the array. Order of growth will help us to compute the running time with ease. We will ignore the lower order terms, since the lower order terms are relatively insignificant for large input. We use different notation to describe limiting behavior of a function.
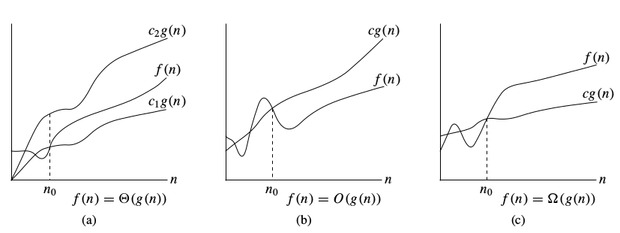
-notation: To denote asymptotic upper bound, we use -notation. For a given function , we denote by (pronounced “big-oh of g of n”) the set of functions: { : there exist positive constants and such that for all }
-notation: To denote asymptotic lower bound, we use -notation. For a given function , we denote by (pronounced “big-omega of g of n”) the set of functions: { : there exist positive constants and such that for all }
-notation: To denote asymptotic tight bound, we use -notation. For a given function , we denote by (pronounced “big-theta of g of n”) the set of functions: { : there exist positive constants and such that for all }
Time complexity notations
While analysing an algorithm, we mostly consider -notation because it will give us an upper limit of the execution time i.e. the execution time in the worst case.
To compute -notation we will ignore the lower order terms, since the lower order terms are relatively insignificant for large input. Let
Lets consider some example:
1.
int count =0;for(int i =0; i < N; i++)for(int j =0; j < i; j++)
count++;
Lets see how many times count++ will run.
When , it will run times. When , it will run times. When , it will run times and so on.
Total number of times count++ will run is . So the time complexity will be .
2.
int count =0;for(int i = N; i >0; i /=2)for(int j =0; j < i; j++)
count++;
This is a tricky case. In the first look, it seems like the complexity is.for theloop andforloop. But its wrong. Lets see why.
Think about how many times count++ will run.
When , it will run times. When , it will run times. When , it will run times and so on.
Total number of times count++ will run is . So the time complexity will be .
The table below is to help you understand the growth of several common time complexities, and thus help you judge if your algorithm is fast enough to get an Accepted ( assuming the algorithm is correct ).
Length of Input (N)
Worst Accepted Algorithm
A lot of students get confused while understanding the concept of time-complexity, but go below you will get in simple :
Imagine a classroom of 100 students in which you gave your pen to one person. Now, you want that pen. Here are some ways to find the pen and what the O order is.
O(n2): You go and ask the first person of the class, if he has the pen. Also, you ask this person about other 99 people in the classroom if they have that pen and so on, This is what we call O(n2).
O(n): Going and asking each student individually is O(N).
O(log n): Now I divide the class into two groups, then ask: “Is it on the left side, or the right side of the classroom?” Then I take that group and divide it into two and ask again, and so on. Repeat the process till you are left with one student who has your pen. This is what you mean by O(log n).
I might need to do the O(n2) search if only one student knows on which student the pen is hidden. I’d use the O(n) if one student had the pen and only they knew it. I’d use the O(log n) search if all the students knew, but would only tell me if I guessed the right side.
NOTE :
We are interested in rate of growth of time with respect to the inputs taken during the program execution .
Another Example: Time Complexity of algorithm/code is not equal to the actual time required to execute a particular code but the number of times a statement executes. We can prove this by using time command. For example, Write code in C/C++ or any other language to find maximum between N numbers, where N varies from 10, 100, 1000, 10000. And compile that code on Linux based operating system (Fedora or Ubuntu) with below command:
gcc program.c – o program
run it with time ./program
You will get surprising results i.e. for N = 10 you may get 0.5ms time and for N = 10, 000 you may get 0.2 ms time. Also, you will get different timings on the different machine. So, we can say that actual time requires to execute code is machine dependent (whether you are using pentium1 or pentiun5) and also it considers network load if your machine is in LAN/WAN. Even you will not get the same timings on the same machine for the same code, the reason behind that the current network load. Now, the question arises if time complexity is not the actual time require executing the code then what is it? The answer is : Instead of measuring actual time required in executing each statement in the code, we consider how many times each statement execute.
#include <stdio.h>
intmain()
{
printf("Hello World");
}
Output
Hello World
In above code “Hello World!!!” print only once on a screen. So, time complexity is constant: O(1) i.e. every time constant amount of time require to execute code, no matter which operating system or which machine configurations you are using. Now consider another code:
#include <stdio.h>
voidmain()
{
inti, n = 8;
for(i = 1; i <= n; i++) {
printf("Hello Word !!!\n");
}
}
Output
Hello Word !!!
Hello Word !!!
Hello Word !!!
Hello Word !!!
Hello Word !!!
Hello Word !!!
Hello Word !!!
Hello Word !!!
In above code “Hello World!!!” will print N times. So, time complexity of above code is O(N).
ADDITIONAL INFORMATION : For example: Let us consider a model machine which has the following specifications: –Single processor –32 bit –Sequential execution –1 unit time for arithmetic and logical operations –1 unit time for assignment and return statements
Pseudocode:
Sum(a,b){
returna+b //Takes 2 unit of time(constant) one for arithmetic operation and one for return.(as per above conventions) cost=2 no of times=1
}
Tsum= 2 = C =O(1)
Sum of all elements of a list :
Pseudocode:
list_Sum(A,n){//A->array and n->number of elements in the array
total =0 // cost=1 no of times=1
fori=0 to n-1 // cost=2 no of times=n+1 (+1 for the end false condition)